Sur le papier, construire vos propres solutions d'enrichissement de données semble judicieux. Vous disposez d’ingénieurs compétents, d’une équipe de data science décente et d’une feuille de route qui semble le permettre. Mais voilà : l’enrichissement des données transactionnelles n’est pas seulement un projet technique, c’est un projet en constante évolution. Et pour de nombreuses banques et fintechs, ce qui commence comme une solution miracle se transforme en passif à long terme.
Alors, creusons plus en détail les coûts inattendus, les pièges temporels et le chaos de bord-case qui tendent à ignorer les équipes qui courent après les solutions d'enrichissement de données maison. Et, bien sûr, la raison pour laquelle nous pensons que la solution Tapix pourrait être un excellent choix pour vous.
L'enrichissement des transactions n'est pas une simple tâche de catégorisation
L'enrichissement des transactions pourrait ressembler à une simple question de mappage des noms des commerçants et d'application de règles pour identifier les catégories. Mais les données du monde réel se comportent rarement de manière aussi prévisible. Avec des descriptions chaotiques de commerçants comme « F.LLI MARINO SNC » ou « B2B PRIME » dans la catégorie « Autre », il est presque impossible de déterminer avec précision ce que le client a acheté sans intelligence contextuelle. Les clients attendent de la clarté, et lorsque leurs applications bancaires affichent des informations cryptiques ou trompeuses, la confiance disparaît rapidement.

C’est là que les API dédiées entrent en jeu. Si vous vous êtes demandé : « Comment puis-je implémenter la catégorisation des paiements dans mon logiciel bancaire ? », la réponse consiste généralement à utiliser une API d’enrichissement des données de transaction conçue pour gérer à grande échelle les entrées désordonnées du monde réel.
En pratique, construire une plateforme d’enrichissement qui s’adapte aux comportements des commerçants en constante évolution, aux nuances régionales et à la mise en forme incohérente n’est pas un projet ponctuel. C’est un investissement continu dans la science des données, l’apprentissage automatique, les boucles de rétroaction et la couverture mondiale.
Le talent n'est pas la contrainte. La concentration l’est
La plupart des équipes fintech sont capables d’embaucher des ingénieurs et des ingénieurs data talentueux. Le défi n’est pas la disponibilité. C’est la priorisation.
Une fois le cadre d'enrichissement initial construit, le véritable travail commence : affiner les modèles, intégrer les commentaires des utilisateurs, surveiller la précision de la classification, traiter les cas périphériques et mettre à jour la logique à mesure que de nouveaux commerçants et modes de paiement émergent.
C'est pourquoi de nombreuses institutions en croissance commencent à se demander : Quels sont les avantages d'utiliser une API d'enrichissement des données de paiement ? La réponse courte ? Un délai de valorisation plus rapide et une meilleure précision et aucune distraction par rapport à vos objectifs principaux de produits.
Coûts opérationnels et de conformité cachés
Les coûts à long terme d'une plateforme d'enrichissement interne vont souvent au-delà des effectifs. Le maintien et l'amélioration d'un tel système introduisent plusieurs niveaux de responsabilité supplémentaires :
- Infrastructure de données : Gestion de l'ingestion, du nettoyage et du stockage sécurisé en temps réel
- QA et surveillance de précision : Assurer la fiabilité de la classification à l'échelle
- Mises à jour continues : Suivre le rythme des changements mondiaux des commerçants et du comportement des consommateurs
- Conformité : Particulièrement importante lorsque les modèles sont formés sur des données sensibles
- Sécurité : Protéger les données enrichies contre les atteintes ou les abus
En outre, la mise en œuvre d'un enrichissement qui fonctionne entre les langues, les monnaies et les structures commerciales régionales ajoute une complexité considérable, en particulier pour les institutions opérant sur plusieurs marchés.
Le coût total de possession des solutions d'enrichissement
Le coût réel de la construction et de la maintenance d'une solution d'enrichissement interne est souvent sous-estimé. Alors que les projections initiales pourraient tenir compte des salaires des ingénieurs et des coûts des serveurs, les dépenses cachées et récurrentes commencent bientôt à apparaître :
Recyclage constant du modèle et corrections manuelles : Même les modèles de machine learning les plus avancés se dégradent avec le temps à mesure que de nouveaux formats commerçants, flux de paiement et modes de dépenses émergent. Les équipes finissent par consacrer des sprints entiers à affiner les bases de données des commerçants et à déboguer les étiquettes incorrectes.
Coordination interne : Les équipes produit exigent une itération rapide, les équipes de conformité doivent vérifier la logique de catégorisation et l'ingénierie doit équilibrer les améliorations de précision avec les priorités de la feuille de route. Les frais généraux liés à l'alignement de ces fonctions augmentent de mois en mois.
Problèmes liés à la clientèle : Les transactions mal étiquetées frustrent les utilisateurs, ce qui entraîne des volumes plus élevés de tickets de support, de remboursements, voire de désabonnements. Chaque erreur nécessite un examen manuel, une escalade interne et des correctifs, détournant l'attention d'autres projets au sein de l'entreprise.
Audits de précision et pipelines de tests : Les équipes internes de QA sont souvent obligées d'effectuer des contrôles approfondis pour éviter les baisses de performance. Le maintien d'une précision de plus de 90 % nécessite un réglage continu du pipeline de données et une validation au niveau commerçant.
Contrôle réglementaire et juridique : Les solutions d'enrichissement de données touchent des données sensibles. Tous les faux pas (des noms de commerçants incorrects ou des transactions de jeu mal classées) peuvent entraîner des maux de tête réglementaires, des amendes ou la méfiance des clients.
En revanche, des solutions tierces comme Tapix offrent des taux de précision supérieurs à 95 %, grâce à des milliards de transactions traitées et à des modèles d’enrichissement propriétaires construits à partir d’années d’expertise dans le domaine. Tapix gère une base de données de commerçants couvrant des centaines de milliers de marques dans le monde, avec reconnaissance de logo et normalisation des métadonnées, le tout mis à jour en temps réel.
Par exemple, Deblock, une application de cryptobanque, a intégré Tapix pour améliorer la clarté autour des transactions complexes liées à la blockchain et a vu la couverture des commerçants augmenter de 25 % et celle des logos atteindre 66 %. De même, bunq, l’une des principales néobanques européennes, a utilisé Tapix pour fournir des informations intelligentes à ses utilisateurs sur leurs comptes personnels et professionnels. Le résultat ? Plus de 90 % de transactions classées par catégorie et 99,9 % de précision des données obtenues.
Les transactions en ligne ajoutent un défi supplémentaire
L'identification précise des transactions e-commerce reste l'un des points d’achoppement les plus persistants et les plus frustrants de l'enrichissement des données. Pour les banques et les fintechs au service des consommateurs et des PME, le défi est simple à décrire mais difficile à résoudre : les processeurs de paiement comme Stripe, PayPal, Adyen et d'autres masquent souvent la véritable identité du commerçant.
Cela devient particulièrement problématique lors de la création d'outils de budgétisation, d'analyses pour les petites entreprises ou de systèmes de soutien à la clientèle qui reposent sur une identification claire des commerçants. Un utilisateur voyant « STRIPE.SNL » ne saura pas s’il a acheté des chaussures ou réservé un service.
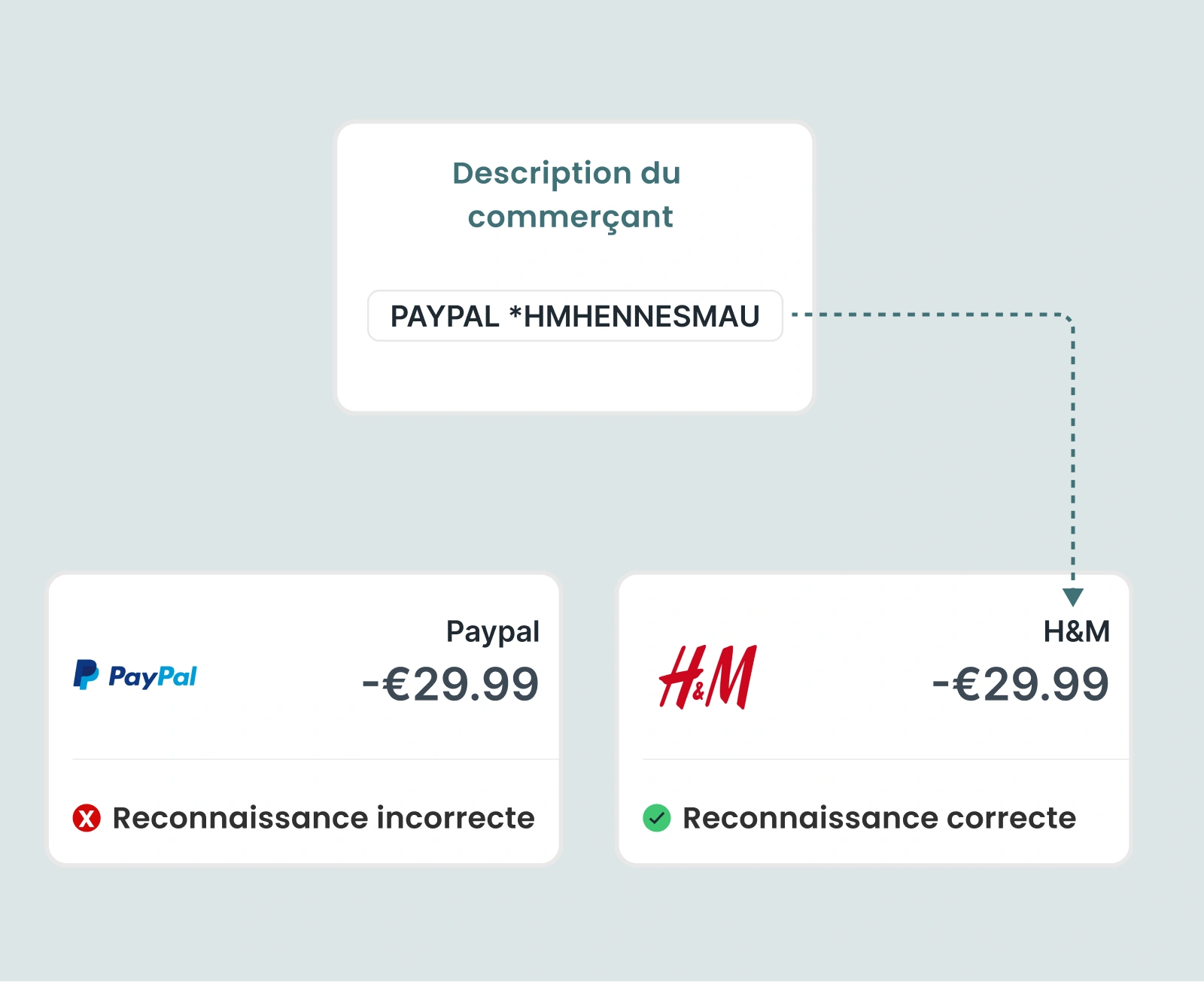
Tapix répond directement à ce problème via un module d'enrichissement spécialisé Payment Gateways. En résolvant les modèles de transaction de toutes les principales passerelles (y compris Stripe, PayPal, Adyen, Square et Braintree) Tapix peut reconstituer avec précision le nom du commerçant original, lui attribuer la catégorie correcte et joindre des métadonnées visuelles cohérentes comme les logos et l'emplacement.
Plutôt que de s'appuyer sur des descripteurs bruts de transactions, Tapix exploite :
- Des graphiques commerçants internes connectant les alias de passerelle avec des noms de marque vérifiés
- Des recherches dynamiques de métadonnées qui interprètent des données de passerelle structurées mais ambiguës
- Des mises à jour en temps réel pour refléter les marques émergentes de commerce électronique ou les plateformes de revendeurs
- Un enrichissement contextuel adapté aux cas d’utilisation grand public et PME
Construire quelque chose de similaire à l'interne nécessiterait l'accès à de vastes données de réseau de commerçants, des boucles de rétroaction cohérentes et des partenariats directs avec les processeurs, dont aucun n'est anodin à établir. Tapix résout ce problème à grande échelle, en permettant aux établissements de proposer des données de transaction plus propres sans compromettre leurs propres ressources.
En conclusion
Construire son propre cadre d’enrichissement peut sembler judicieux et stratégique mais, pour la plupart des banques et des fintechs, cela finit par être un détournement coûteux des priorités essentielles.
Il est absolument essentiel d'embaucher des personnes brillantes qui comprennent vos données. Mais ce ne sont pas elles qui devraient réinventer les pipelines d'enrichissement à partir de zéro. Leur temps est mieux consacré à l'interprétation des données : la transformation des idées en action et la stratégie en croissance. Les données elles-mêmes ? C’est pour elles que nous sommes là.
Pour plus de détails sur les avantages que ces solutions peuvent apporter à votre banque, consultez les offres de Tapix.
